시계열 데이터(Time-Series Data)
시계열 데이터란 시간의 흐름에 따라 일정하게 순차적으로 기록된 데이터를 의미한다.
대표적으로 날씨, 전기사용량, 주식 데이터 등이 존재한다.

예시로 위 사진은 구글에 SNP500을 검색했을 때 나오는 주가 데이터 시각화 결과이고
아래 사진은 실제 SNP500 index 데이터이다.
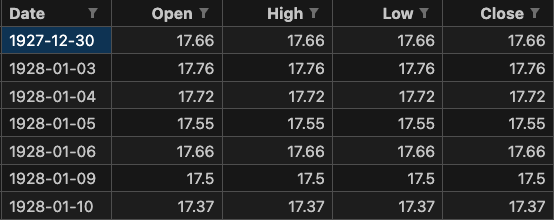
실제 시계열 데이터는 다음과 같이 시간에 흐름에 따라 일정하게 기록되어있으며 주로 csv파일(엑셀) 형식으로 저장된다.
그렇다면 시계열 예측은 무엇일까?
시계열 예측(Time-Series Forecasting)
시계열 예측은 과거 관측된 시계열 데이터를 분석하여 관측되지 않은 미래의 시계열 데이터를 예측하는 문제이다.
대표적으로 주가를 예측하거나 상품의 수요를 예측하는 문제가 있다.
예시를 통해 쉽게 알아보자
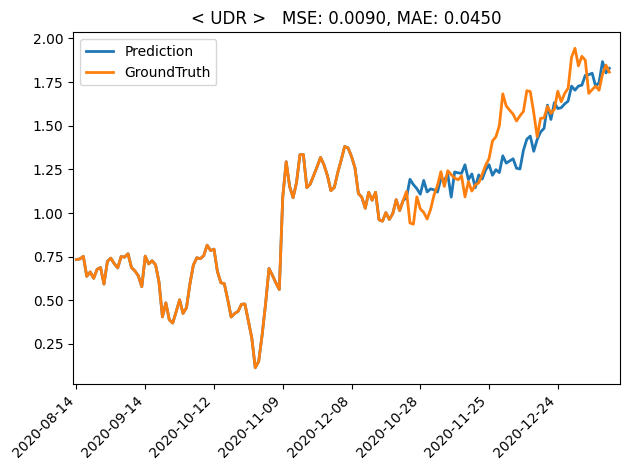
위 이미지는 관측된 96일치의 시계열 데이터를 토대로 60일치의 미래 데이터를 예측한 결과이다.
주황색이 예측하고자하는 데이터, 실제값을 나타내고 파란색이 예측한 데이터, 예측값을 나타낸다.
전체적인 추세를 잘 예측한 사례이지만 디테일한 변곡점은 제대로 예측하지 못하는 모습을 볼 수 있다.
시계열 예측을 알아봤으니 이제 시계열 예측이 실제로 어떻게 이루어지는지 단계별로 알아보자.
1. 데이터 수집 및 전처리: 배포된 데이터셋을 사용하거나 크롤링을 통해 시계열 데이터를 수집하고 수집된 데이터를 예측에 사용할 수 있도록 가공하는 단계. 전처리 과정으로는 결측치와 이상치 처리, 정규화(Normalization) 등이 있다.
2. 데이터 분석: 수집된 데이터를 시각화나 통계적 분석 방법을 이용하여 확인하는 단계. 주로 데이터가 어떤 분포, 추세, 계절성을 지니는지 확인한다.
3. 모델 선정: 예측을 위해 사용하고자하는 인공지능(AI) 모델을 선정하는 단계. 추천하는 딥러닝 모델로는 ARIMA, PatchTST, iTransformer 등이 있다.
4. 모델 학습: 선정된 모델을 예측하고자하는 데이터로 학습 시키는 단계. 모델은 학습 데이터(Train data)를 입력받아 예측하고 오차를 통해 모델을 업데이트하는 과정을 반복한다.
5. 모델 평가: 학습이 완료된 모델의 성능을 평가하는 단계. 주로 MSE(Mean Squared Error)와 MAE(Mean Absolute Error)를 통해 모델의 성능을 평가하며 테스트 데이터(Test data)를 가지고 평균 오차를 계산한다.
6. 데이터 예측: 모델을 가지고 아직 관측되지 않은 미래 기간의 데이터를 예측하는 단계. 과거 데이터를 통해 예측하고자하는 미래 데이터를 예측한다.
이렇게 총 6개의 프로세스를 걸쳐서 시계열 예측이 이루어진다.
실제로 시계열 예측은 다양한 분야에서 사용되며 미래를 예측하고자하는 강력한 작업이다.
오랜 기간 연구된 Task이고 다양한 머신러닝, 딥러닝 모델들이 존재하지만 아직 완벽하게 예측하는 성능은 기대할 수 없다.
'Time-Series Forecasting' 카테고리의 다른 글
| [논문 리뷰] Pyraformer: Low-Complexity Pyramidal Attention for Long-Range Time Series Modeling and Forecasting (2) | 2025.05.27 |
|---|---|
| 시계열 예측 논문에서 자주 사용하는 기본 Notation 정리 (1) | 2025.05.27 |
